
Base全家桶汇总
base16
使用16个ASCII可打印字符(数字0-9和字母A-F),对任意字节数据进行编码。
先获取输入字符串每个字节的二进制值(不足8比特在高位补0),然后将其串联进来,再按照4比特一组进行切分,将每组二进制数分别转换成十进制。
Base16编码后的数据量是原数据的两倍:1000比特数据需要250个字符(即 250*8=2000 比特)。
编码表:

特征:密文由16个字符(0-9,A-F)组成
base32
Base32编码是使用32个可打印字符(字母A-Z和数字2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
Base32主要用于编码二进制数据,但是Base32也能够编码诸如ASCII之类的二进制文本。
Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。
编码表:
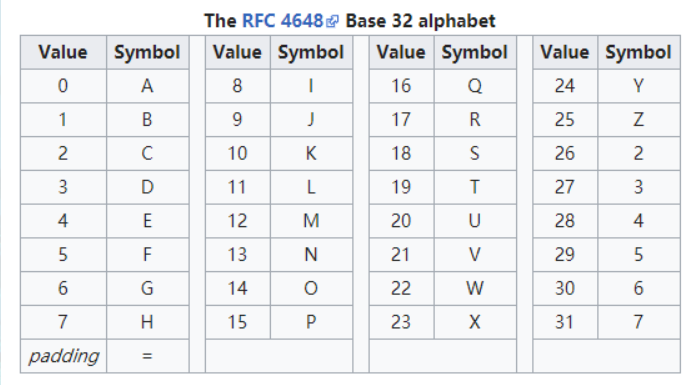
特征:密文由32个字符(A-Z,2-7)组成,末尾可能会有‘=’,但最多有6个
base36
Base36是一个二进制到文本编码表示方案的二进制数据以ASCII通过将其转化为一个字符串格式基数 -36 表示。选择36十分方便,因为可以使用阿拉伯数字 0–9和拉丁字母 A–Z 表示数字。
每个base36位需要少于6位的信息来表示。
特征:密文由36个字符(0-9,a-z)组成,加密仅支持整数数字,解密仅支持字符串,不支持中文 密文由36个字符(0-9,A-Z)
base58
Base58是用于Bitcoin中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址。
相比Base64,Base58不使用数字”0”,字母大写”O”,字母大写”I”,和字母小写”l”,以及”+”和”/“符号
编码表:
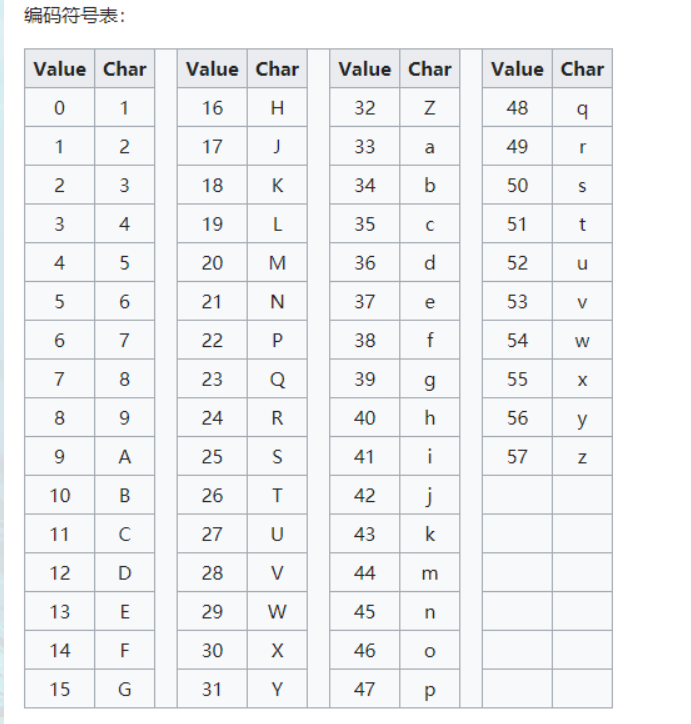
特征:Base58不使用数字”0”,字母大写”O”,字母大写”I”,和字母小写”l”,以及”+”和”/”符号
base62
Base62编码将数字转换为ASCII字符串(0-9,az和AZ),反之亦然,这通常会导致字符串较短。
26个小写字母+26个大写字母+10个数字=62
特征: 密文由62字符(0-9,a-z,A-Z)组成
在线网站:https://base62.io/ (支持中文)
在线网站:http://decode-base62.nichabi.com http://ctf.ssleye.com/base62.html (仅支持数字)
base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方=64,所以每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法。
编码表:
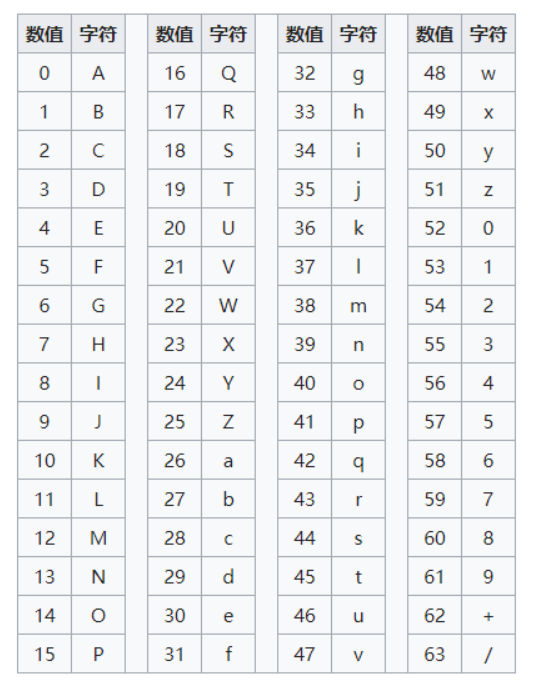
特征: 密文由64个字符(A-Z,a-z,0-9,+,/)组成,末尾可能会出现1或2个’=’ 最多有2个
- 附加: ida反汇编中常见base64加密
特征:
(1)、密文中会出现“=”等号。
(2)、有64个可见字符。
(3)、代码中含有0xF、0x3F、0x3等符号
示例1:
void *__cdecl sub_411AB0(char *a1, unsigned int a2, int *a3)
{
int v4; // STE0_4
int v5; // STE0_4
int v6; // STE0_4
int v7; // [esp+D4h] [ebp-38h]
signed int i; // [esp+E0h] [ebp-2Ch]
unsigned int v9; // [esp+ECh] [ebp-20h]
int v10; // [esp+ECh] [ebp-20h]
signed int v11; // [esp+ECh] [ebp-20h]
void *Dst; // [esp+F8h] [ebp-14h]
char *v13; // [esp+104h] [ebp-8h]
if ( !a1 || !a2 )
return 0;
v9 = a2 / 3;
if ( (signed int)(a2 / 3) % 3 )
++v9;
v10 = 4 * v9;
*a3 = v10;
Dst = malloc(v10 + 1);
if ( !Dst )
return 0;
j_memset(Dst, 0, v10 + 1);
v13 = a1;
v11 = a2;
v7 = 0;
while ( v11 > 0 )
{
byte_41A144[2] = 0;
byte_41A144[1] = 0;
byte_41A144[0] = 0;
for ( i = 0; i < 3 && v11 >= 1; ++i )
{
byte_41A144[i] = *v13;
--v11;
++v13;
}
if ( !i )
break;
switch ( i )
{
case 1:
*((_BYTE *)Dst + v7) = aAbcdefghijklmn[(signed int)(unsigned __int8)byte_41A144[0] >> 2];
v4 = v7 + 1;
*((_BYTE *)Dst + v4++) = aAbcdefghijklmn[((byte_41A144[1] & 0xF0) >> 4) | 16 * (byte_41A144[0] & 3)];
*((_BYTE *)Dst + v4++) = aAbcdefghijklmn[64];
*((_BYTE *)Dst + v4) = aAbcdefghijklmn[64];
v7 = v4 + 1;
break;
case 2:
*((_BYTE *)Dst + v7) = aAbcdefghijklmn[(signed int)(unsigned __int8)byte_41A144[0] >> 2];
v5 = v7 + 1;
*((_BYTE *)Dst + v5++) = aAbcdefghijklmn[((byte_41A144[1] & 0xF0) >> 4) | 16 * (byte_41A144[0] & 3)]; //这里出现了3
*((_BYTE *)Dst + v5++) = aAbcdefghijklmn[((byte_41A144[2] & 0xC0) >> 6) | 4 * (byte_41A144[1] & 0xF)]; //这里就是出现了0xF
*((_BYTE *)Dst + v5) = aAbcdefghijklmn[64]; //出现64位,且看数组名字,寻回的话,应该能发现数组数据对应base64加密
v7 = v5 + 1;
break;
case 3:
*((_BYTE *)Dst + v7) = aAbcdefghijklmn[(signed int)(unsigned __int8)byte_41A144[0] >> 2];
v6 = v7 + 1;
*((_BYTE *)Dst + v6++) = aAbcdefghijklmn[((byte_41A144[1] & 0xF0) >> 4) | 16 * (byte_41A144[0] & 3)]; //这里出现了3
*((_BYTE *)Dst + v6++) = aAbcdefghijklmn[((byte_41A144[2] & 0xC0) >> 6) | 4 * (byte_41A144[1] & 0xF)]; //这里就是出现了0xF
*((_BYTE *)Dst + v6) = aAbcdefghijklmn[byte_41A144[2] & 0x3F]; //这里出现了0x3F
v7 = v6 + 1;
break;
}
}
*((_BYTE *)Dst + v7) = 0;
return Dst;
}示例2:
signed int __cdecl base64_decode(BYTE *p_str_base64, int str_len, int p_out_bytes, int p_bytes_get)
{
signed int result; // eax@3
int v5; // [sp+0h] [bp-1Ch]@11
int sum; // [sp+4h] [bp-18h]@7
int suma; // [sp+4h] [bp-18h]@17
signed int i; // [sp+8h] [bp-14h]@7
int j; // [sp+8h] [bp-14h]@17
signed int bits_count; // [sp+Ch] [bp-10h]@7
int n_output_bytes; // [sp+10h] [bp-Ch]@4
unsigned int v12; // [sp+14h] [bp-8h]@4
signed int f_dontoutput; // [sp+18h] [bp-4h]@4
if ( p_str_base64 && p_bytes_get )
{
v12 = (unsigned int)&p_str_base64[str_len];
n_output_bytes = 0;
f_dontoutput = p_out_bytes == 0;
while ( (unsigned int)p_str_base64 < v12 && *p_str_base64 )
{
sum = 0;
bits_count = 0;
for ( i = 0; i < 4 && (unsigned int)p_str_base64 < v12; ++i )// 每4个字符换3个字节
{
v5 = sub_15E88A0((char)*p_str_base64++); //v5等于base64字符对应的数
if ( v5 == -1 )
{
--i;
}
else
{ // 应该是base64算法
sum = v5 | (sum << 6); // 2^6=64 高位编码在前
bits_count += 6; //
}
}
if ( !f_dontoutput && n_output_bytes + bits_count / 8 > *(_DWORD *)p_bytes_get )
f_dontoutput = 1;
suma = sum << (24 - bits_count);
for ( j = 0; j < bits_count / 8; ++j )
{
if ( !f_dontoutput )
*(_BYTE *)p_out_bytes++ = ((unsigned int)byte_FF0000 & suma) >> 16;
suma <<= 8;
++n_output_bytes;
}
} // while
*(_DWORD *)p_bytes_get = n_output_bytes;
if ( f_dontoutput )
result = 0;
else
result = 1;
}
else
{
result = 0;
}
return result;
}脚本:
import base64 import string str1 = "x2dtJEOmyjacxDemx2eczT5cVS9fVUGvWTuZWjuexjRqy24rV29q" string1 = "ZYXABCDEFGHIJKLMNOPQRSTUVWzyxabcdefghijklmnopqrstuvw0123456789+/" string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
str1是要解密的代码
string1是改过之后的base64表
转载于:https://www.cnblogs.com/dyhaohaoxuexi/p/11025985.html
base85
base85 也称为Ascii85,是Paul E. Rutter为btoa实用程序开发的一种二进制文本编码形式。通过使用五个ASCII字符来表示四个字节的二进制数据(使编码量1 / 4比原来大,假设每ASCII字符8个比特),它比更有效UUENCODE或Base64的,它使用四个字符来表示三个字节的数据(1 / 3的增加,假设每ASCII字符8个比特)
与Base64一样,Base85编码的目标是对二进制数据可打印的ASCII字符进行编码。但是它使用了更大的字符集,因此效率更高一些。具体来说,它可以用5个字符编码4个字节(32位)
base91
base91需要91个字符来表示ASCII编码的二进制数据。 从94个可打印ASCII字符(0x21-0x7E)中,以下三个字符被省略以构建basE91字母:
-(破折号,0x2D)
\(反斜杠,0x5C)
'(撇号,0x27)basE91是将二进制数据编码为ASCII字符的高级方法。
它类似于UUencode或base64,但效率更高。 base91产生的开销取决于输入数据。 它的数量最多为23%(而base64为33%),范围可以降低到14%,通常发生在0字节块上。
编码表:
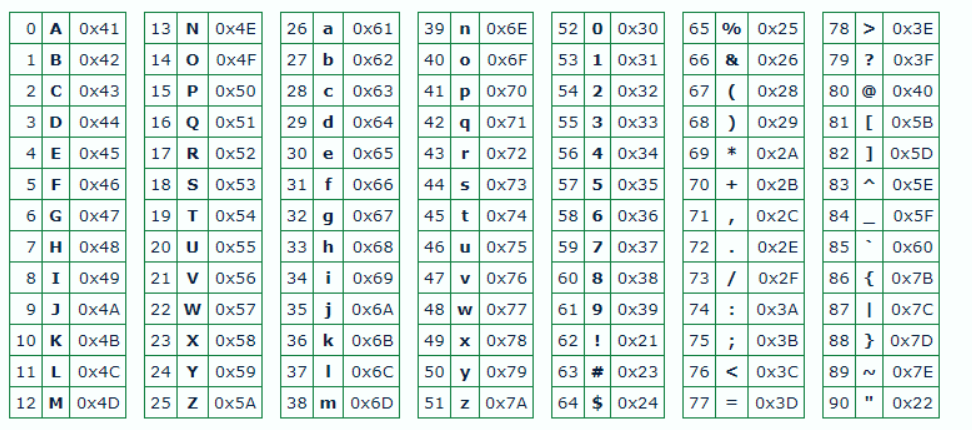
特征: 密文由91个字符(0-9,a-z,A-Z,!#$%&()*+,./:;<=>?@[]^_`{|}~”)组成

